Here’s a complete architecture of how Infyn works under the hoodDocumentation Index
Fetch the complete documentation index at: https://docs.infyn.dev/llms.txt
Use this file to discover all available pages before exploring further.
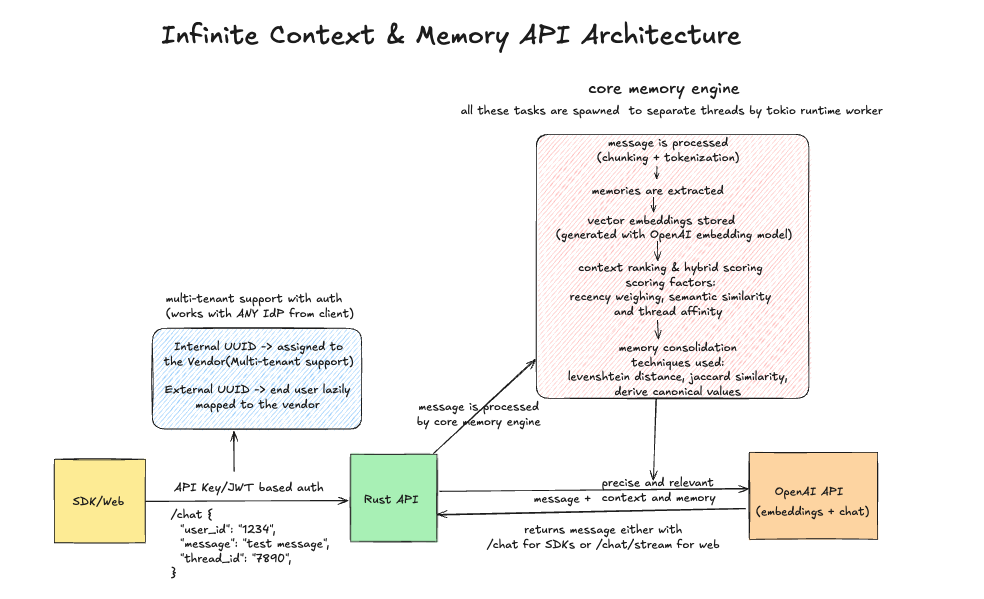
Overview of the Infinite Context & Memory API
This architecture is designed to provide AI agents with a long-term, seemingly infinite memory. The system is built around a centralRust API that orchestrates interactions between the client, a specialized Core Memory Engine, and the OpenAI API.
Step-by-Step Flow
-
Request Initiation (SDK/Web)
The process begins when a client application (via an SDK or web interface) sends a request to the
/chatendpoint. This request is secured with an API Key or JWT and contains the user’s message, a uniqueuser_id, and athread_idto maintain conversational context. -
Authentication & Routing (Rust API)
The
Rust APIfirst authenticates the request. It supports a multi-tenant structure where each vendor (client of the API) is assigned an internal UUID. The end-user’s ID is then mapped to that vendor, ensuring data isolation and security. -
Asynchronous Memory Processing (Core Memory Engine)
The user’s message is passed to the
Core Memory Engine. This engine operates asynchronously on separate threads for high performance. Its primary role is to manage the system’s memory:- Processing & Embedding: The message is broken down, and key memories are extracted. These are then converted into vector embeddings using an OpenAI model and stored.
- Ranking & Scoring: To retrieve relevant context for the current message, the engine ranks existing memories using factors like recency, semantic similarity, and conversational thread affinity.
- Consolidation: To keep the memory store efficient and accurate, techniques like Levenshtein distance and Jaccard similarity are used to consolidate similar memories and derive canonical values, preventing redundancy.
-
Context-Aware Prompting (OpenAI API)
The
Core Memory Enginereturns the most precise and relevant context to theRust API. This retrieved memory is combined with the original user message to create a rich, context-aware prompt. This complete prompt is then sent to the OpenAIchatAPI. -
Response Generation & Delivery
OpenAI processes the enriched prompt and generates a response. This response is sent back to the
Rust API, which then forwards it to the original client. The API offers flexible delivery, either as a complete response for SDKs or as a stream for real-time web interfaces.